
Edit 02/26: access to the repo for this code here
The Ionic team has been hard at work trying to lower the barrier of entry in the mobile development world.
The Ionic Creator is a simple prototyping tool that helps developers, designers, and project managers to quickly build mobile apps and websites without having to code.
This allows for a quick feedback loop among a team which helps speed up the development process drastically. A project manager might prototype a design and generate real, clean Ionic code to give to a developer. Or, a developer might use Creator to quickly generate UI snippets and rapidly bootstrap new app projects.
Unfortunately, as of now, dynamic data prototyping is not directly supported in the tool and this tutorial aims at highlighting how this can be done.
What is Creator ?
As Matt Kremer puts it in the very first Ionic Creator tutorial video: “Ionic Creator is a simple drag and drop prototyping tool to create real app with the touch of your mouse.”
Indeed, Ionic Creator is provides a full set of Ionic components that you can simply drag and drop into your project and rapidly prototype a fully working app.

Who is Ionic Creator for?
- Novice Developers trying to get their hand in hybrid mobile development
- Designers tweaking around options for product development
- Experienced Ionic developers looking to bootstrap their projects
- Freelance developers gathering clients feedback via sharing features
Collaborate, Share and Export your App
Ionic Creator makes it simple to collaborate and share your app in many ways.
You can send a link to the app running in the browser via URL, Email or SMS so a user can run the app from a browser.
Using the Creator App (available on Android & iOS), you can share the app and have it run directly on the device in similar conditions as if it was a stand alone app.
Finally, you can package your app for iOS and/or Android directly through the Ionic Package service.
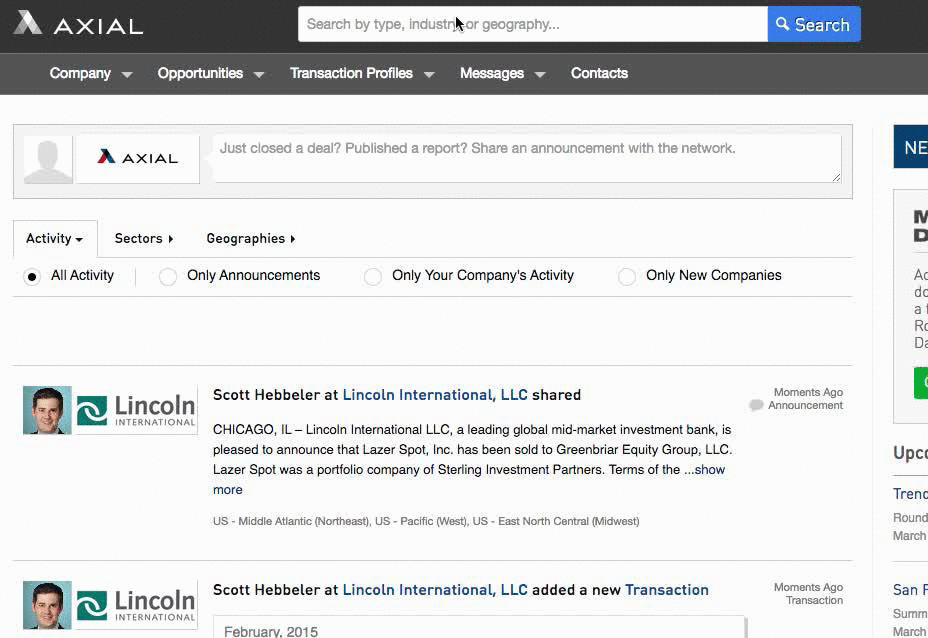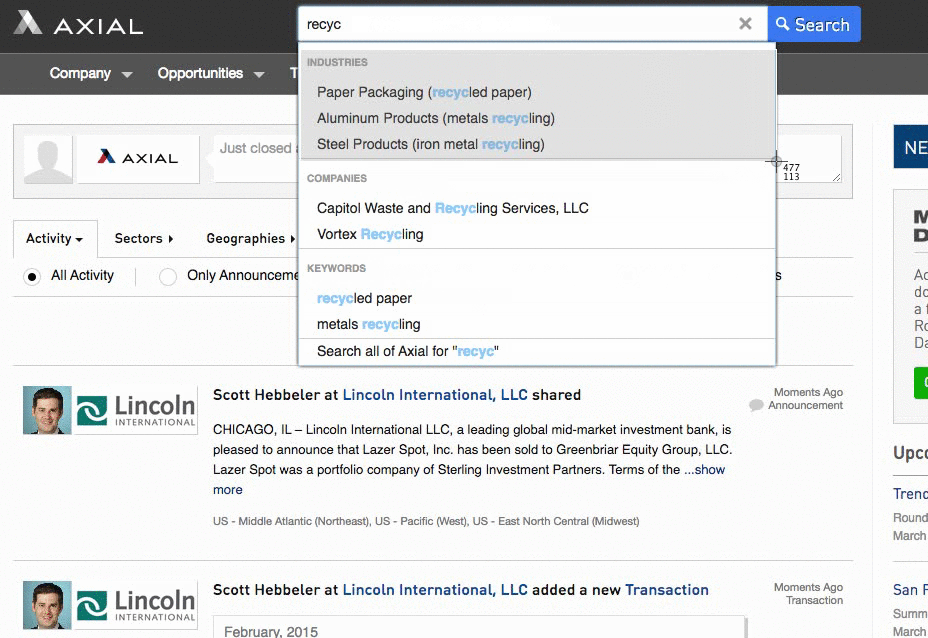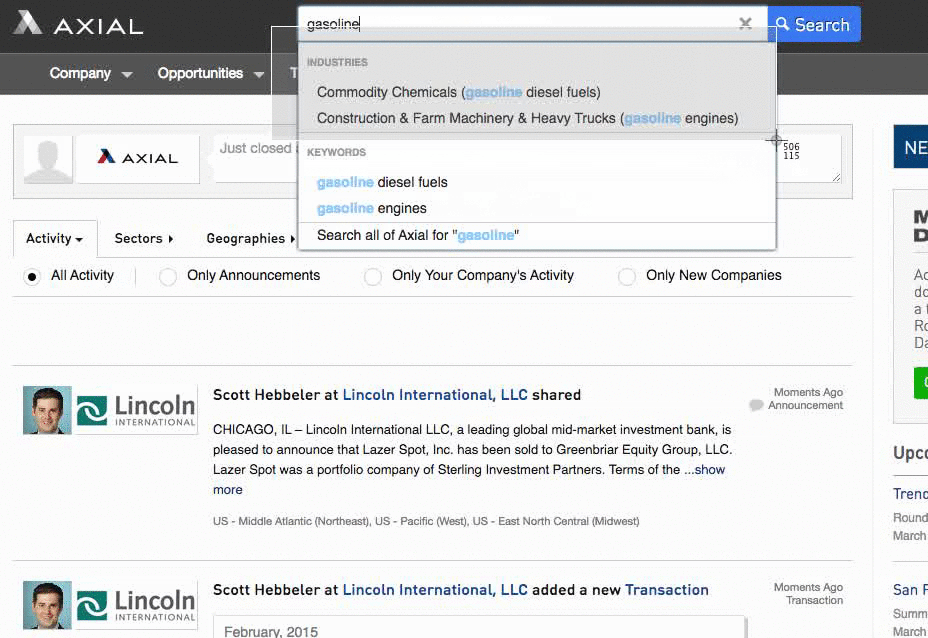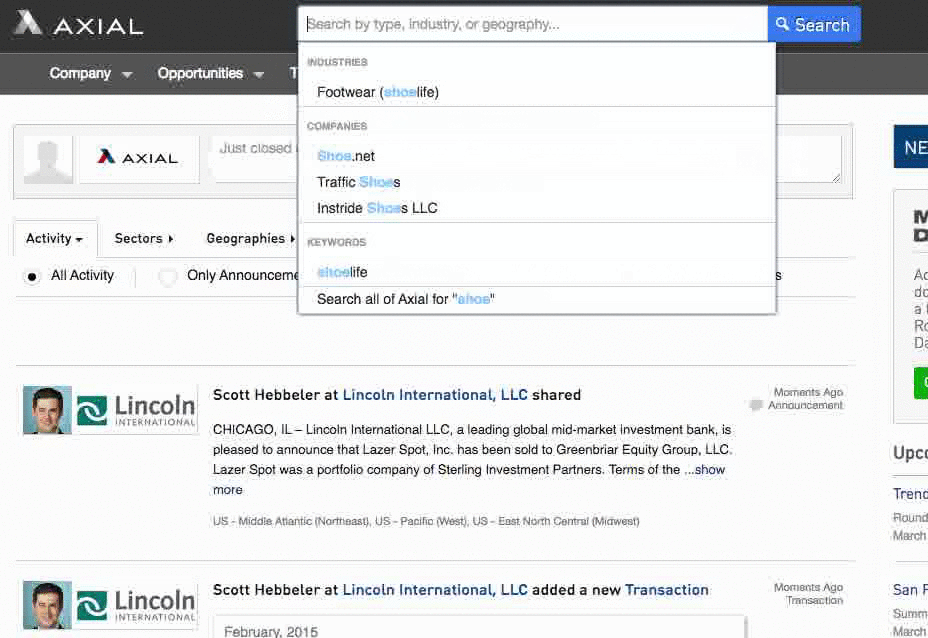
Introducing Axial Events!
The goal of v1 of the app is to show a list of events and allow the member to indicate which other attendees they want to meet up with so we can send reminders during the event.
We will need:
- List of Events: title, content, image
- Event Detail page: list of attendees with a way to indicate interest
Step 1: Project Creation
First we will pick a blank project as we do not need a side menu or a tab layout.
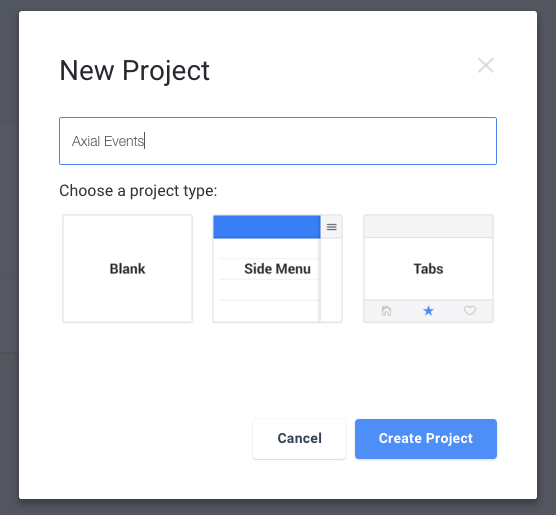
Step 2: Create the list of Events
Then, let’s rename the new page as Events, drag in some List Item w/ Thumbnail and give each of them some details.
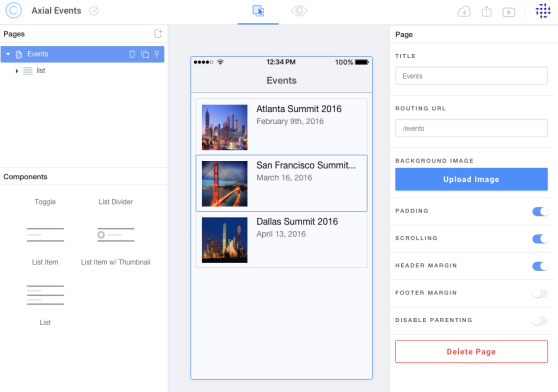
Step 3: Create Event details page
For each event, we will need to create a detail page which we will name according to the event and add a list of List Item w/ Thumbnail for the attendees:
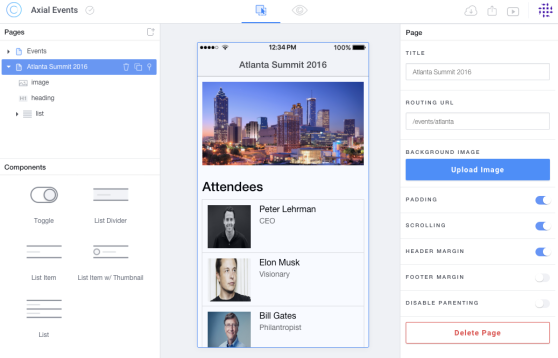
Step 4: link everything together!
Finally, for each item in our events list, let’s adjust the link to their respective
target page:
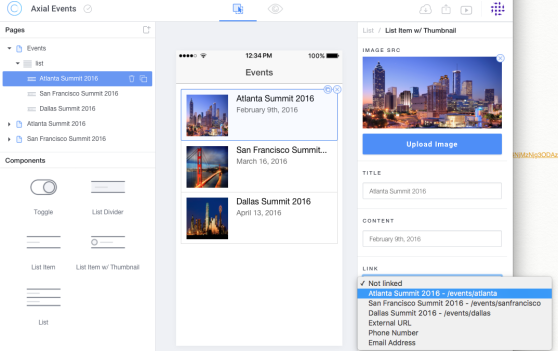
Step 5: let’s take it out in the wild!
At this point, we have an app that showcases how the flow will go from screen to screen.
Let’s take it live and plug it to our API. It’s time to export our app.

Once you open the repository in your favorite text editor, everything has been wired up for you.
With a little bit of Angular knowledge, and a dash of CSS, the sky is the limit!
Let’s clean up the code a bit and plug in our API.
Step 6: Cleanup - Views - Events
First let’s clean up the Events List view and make use of repeating element:
<br /><img src="img/6YS77136Q5yo9V7yjI6g_Atlanta-Summit-hero-image.jpg" alt="" /> <h2>Atlanta Summit 2016</h2> February 9th, 2016 <img src="img/oQ9mqXNQzeoPtXXwzXzZ_san-francisco-summit-hero-image.jpg" alt="" /> <h2>San Francisco Summit 2016</h2> March 16, 2016 <img src="img/WTUsCmmCQjWl43vRjGOx_dallas-summit-homepage-image.jpg" alt="" /> <h2>Dallas Summit 2016</h2> April 13, 2016
then becomes:
<br /><img alt="" />
<h2>{{::event.title}}</h2>
{{::event.date}}
Step 6: Cleanup - Views - Event Info
When duplicating the Event Details page, we created three identical page which should really be one template instead. Therefore, atlantaSummit2016.html, dallasSummit2016.html and sanFranciscoSummit2016.html are replaced by one event.html file which ressembles:
<div style="text-align:center;"><img alt="" width="100%" height="auto" /></div>
<h3>Attendees</h3>
<img alt="" />
<h2>{{::attendee.name}}</h2>
{{::attendee.title}}
Step 6: Cleanup - Routes
Since we have removed the duplicated views, we need to clean up the routes.js file a little from this:
$stateProvider
.state('events', {
url: '/events',
templateUrl: 'templates/events.html',
controller: 'eventsCtrl'
})
.state('atlantaSummit2016', {
url: '/events/atlanta',
templateUrl: 'templates/atlantaSummit2016.html',
controller: 'atlantaSummit2016Ctrl'
})
.state('sanFranciscoSummit2016', {
url: '/events/sanfrancisco',
templateUrl: 'templates/sanFranciscoSummit2016.html',
controller: 'sanFranciscoSummit2016Ctrl'
})
.state('dallasSummit2016', {
url: '/events/dallas',
templateUrl: 'templates/dallasSummit2016.html',
controller: 'dallasSummit2016Ctrl'
});
to this:
$stateProvider
.state('events', {
url: '/events',
templateUrl: 'templates/events.html',
controller: 'eventsCtrl'
})
.state('event', {
url: '/events/:id',
templateUrl: 'templates/event.html',
controller: 'eventCtrl'
});
Step 6: Adjust Controllers
Instead of one controller per event, we will need one eventCtrl controller:
angular
.module('app.controllers', [])
.controller('eventsCtrl', function($scope) {
})
.controller('atlantaSummit2016Ctrl', function($scope) {
})
.controller('sanFranciscoSummit2016Ctrl', function($scope) {
})
.controller('dallasSummit2016Ctrl', function($scope) {
})
then becomes:
angular
.module('app.controllers', [])
.controller('eventsCtrl', function($scope, EventsService) {
$scope.events = [];
EventsService.getEvents().then(function(res) {
$scope.events = res;
});
})
.controller('eventCtrl', function($scope, $stateParams, EventsService) {
$scope.event = [];
EventsService.getEventDetails($stateParams.id).then(function(res) {
$scope.event = res;
EventsService.getEventAttendees($stateParams.id).then(function(res) {
$scope.event.attendees = res;
});
});
})
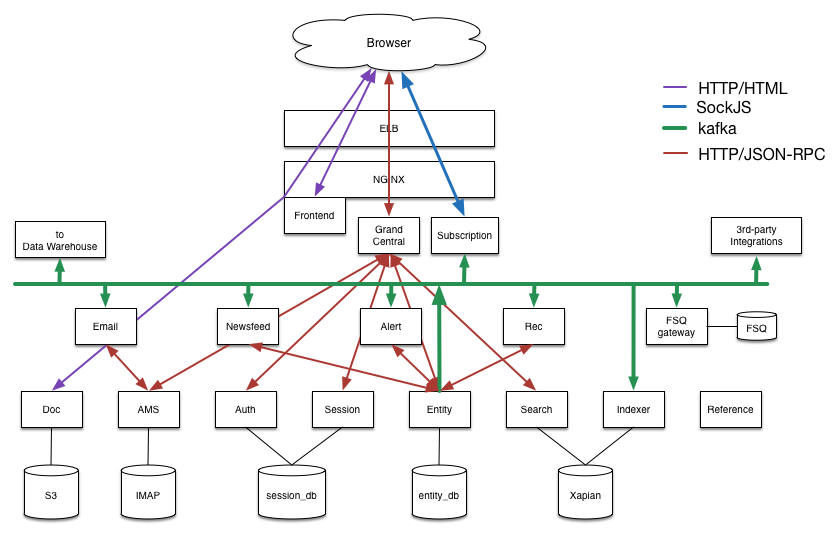
Step 6: Implement Services
First of all, we need to put together a quick API which will provide data manipulation layer for our app.
For the purpose of this demo, I put together a quick Express API running with nodeJS available here.
Given the API is now running at http://localhost:3412/, we have the following endpoints:
- GET /events
- GET /events/:id
- GET /events/:id/attendees
Let’s plug all those in our EventsService:
angular.module('app.services', [])
.service('EventsService', ['$http',
function($http) {
return {
getEvents: function() {
var promise = $http.get('http://localhost:3412/events').then(function (response) {
return response.data;
}, function (response) {
console.log(response);
});
return promise;
},
getEventDetails: function(id) {
var promise = $http.get('http://localhost:3412/events/'+id).then(function (response) {
return response.data;
}, function (response) {
console.log(response);
});
return promise;
},
getEventAttendees: function(id) {
var promise = $http.get('http://localhost:3412/events/'+id+'/attendees').then(function (response) {
return response.data;
}, function (response) {
console.log(response);
});
return promise;
}
}
}
]);
Step 7: Serve!
At this point, we have our app connected to a working API and we are ready to publish!
Display the app in a browser with android and iOS version side by side
$ ionic serve --lab
Build and run the app in iOS simulator
$ ionic build ios && ionic run ios
Build and run the app in android simulator
$ ionic build android && ionic run android
Package your app for store publication via Ionic package
$ ionic package build ios --profile dev
Resources
Ionic Framework - http://ionicframework.com/
Ionic Services - http://ionic.io/
Ionic Creator - http://usecreator.com
Ionic Creator Tutorial Videos on Youtube
Ionic Package - http://blog.ionic.io/build-apps-in-minutes-with-ionic-package/
Find help on Slack - http://ionicworldwide.herokuapp.com/
 “Being the first to respond to a deal on Axial gives you a 19% greater chance to closing it.” -
“Being the first to respond to a deal on Axial gives you a 19% greater chance to closing it.” - 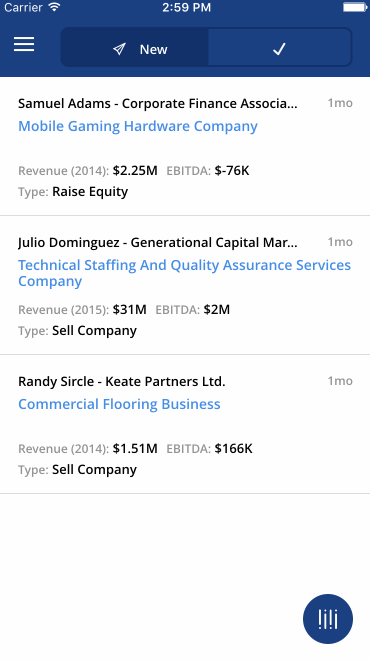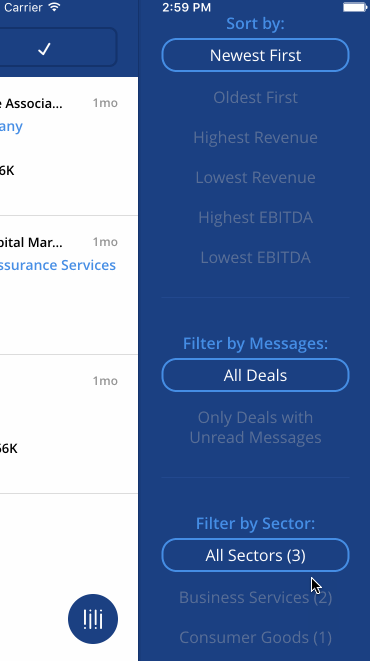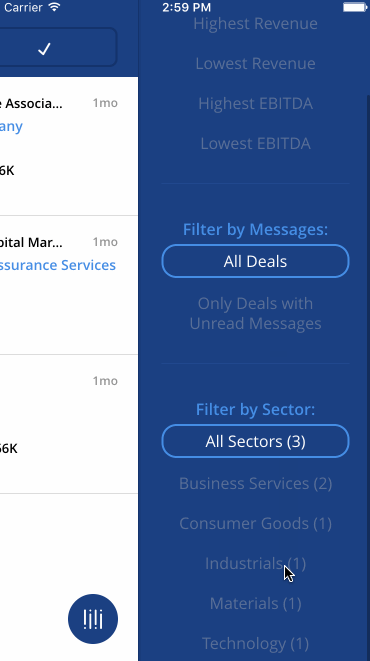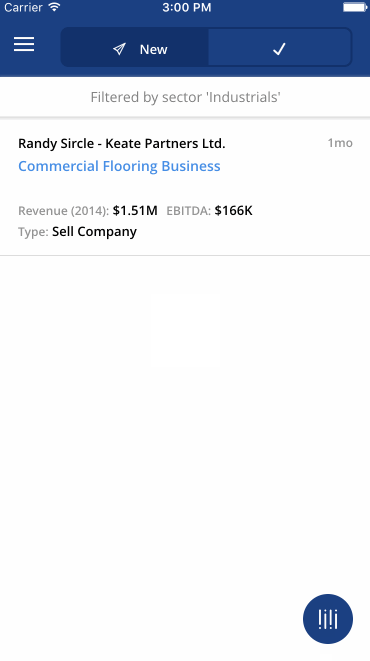
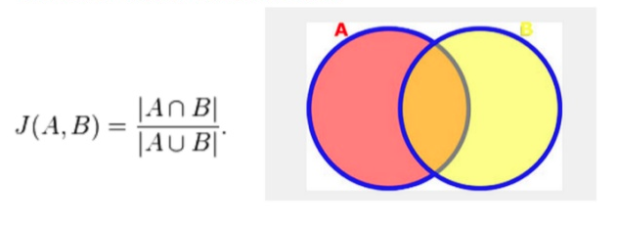
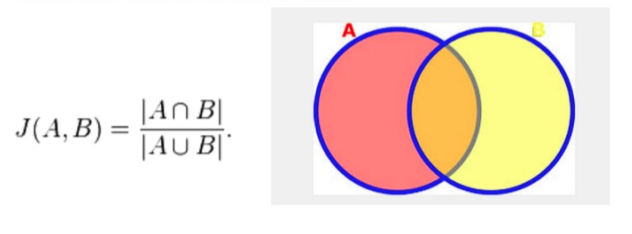
---\frac{A-\cap-B}{A-\cup-B}-bg-ffffff-fg-36312d-s-0.jpg "jaccard(A, B) = \frac{A \cap B}{A \cup B}")
---\frac{A_1-\cap-A_2--\ldots--A_{n_1}-\cap-A_n}{A_1-\cup-A_2--\ldots--A_{n-1}-\cup-A_n}--bg-ffffff-fg-36312d-s-0.jpg "jaccard(A_1, \ldots, A_n) = \frac{A_1 \cap A_2, \ldots, A_{n_1} \cap A_n}{A_1 \cup A_2, \ldots, A_{n-1} \cup A_n}")





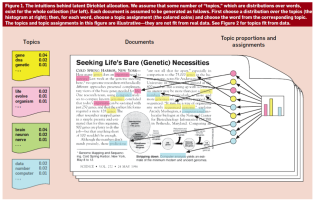


 distances (
distances ( ,
,  , Chebyshev), cosine, correlation, span-norm, Bhattacharyya, Hellinger and Jensen Shannon Divergence. Based on some experimentation, we decided to use Jensen Shannon Divergence(JSD) to measure the distance between documents.
, Chebyshev), cosine, correlation, span-norm, Bhattacharyya, Hellinger and Jensen Shannon Divergence. Based on some experimentation, we decided to use Jensen Shannon Divergence(JSD) to measure the distance between documents.---\displaystyle\sum_i-X(i)-ln-\frac{X(i)}{Y(i)}-bg-ffffff-fg-36312d-s-0.jpg "KL(X || Y) = \displaystyle\sum_i X(i) ln \frac{X(i)}{Y(i)}") . This is a nice way to measure the difference between a probability distribution comparing to
. This is a nice way to measure the difference between a probability distribution comparing to  which is a reference distribution. One way to reason about this distance metric is to assume two probability distributions are exactly the same. Then,
which is a reference distribution. One way to reason about this distance metric is to assume two probability distributions are exactly the same. Then, }{Y(i)}-bg-ffffff-fg-36312d-s-0.jpg "ln \frac{X(i)}{Y(i)}") would be zero. They are exactly same, so the distance is 0. Why
would be zero. They are exactly same, so the distance is 0. Why  , you may ask and that is related to information theory. KL Divergence is also called relative entropy, so one could think the KL divergence as how much information is gained from
, you may ask and that is related to information theory. KL Divergence is also called relative entropy, so one could think the KL divergence as how much information is gained from  assuming that
assuming that -\neq-KL(Y----X)-bg-ffffff-fg-36312d-s-0.jpg "KL(X || Y) \neq KL(Y || X)") and that is a big problem as we cannot create a proper measure of between two observations without considering which is the reference and which one is the one that we measure the distance between the reference vector. In order to prevent this issue, there is a Symmetrised version(well sort of) which just sums up two different KL divergence between each other(
and that is a big problem as we cannot create a proper measure of between two observations without considering which is the reference and which one is the one that we measure the distance between the reference vector. In order to prevent this issue, there is a Symmetrised version(well sort of) which just sums up two different KL divergence between each other(---KL(Y----X)-bg-ffffff-fg-36312d-s-0.jpg "KL(X || Y) + KL(Y || X)") in order to reach a symmetrised version of KL Divergence, but we have another way to measure the distance as well, which is most probably obvious at this point.
in order to reach a symmetrised version of KL Divergence, but we have another way to measure the distance as well, which is most probably obvious at this point.---\frac{1}{2}-KL(X----A)---\frac{1}{2}-KL(Q----A)--bg-ffffff-fg-36312d-s-0.jpg "JSD(X || Y) = \frac{1}{2} KL(X || A) + \frac{1}{2} KL(Q || A)")
 :
:--bg-ffffff-fg-36312d-s-0.jpg "A = \frac{1}{2} (X+Y)")
---JSD(Y----X)--bg-ffffff-fg-36312d-s-0.jpg "JSD(X || Y) = JSD(Y || X)")


{kind=link}